这个系列居然写到(四)了!真不容易!!今年是AI画画的又一次技术大爆炸,蹭一下热点把最近流行的一些新技术和之前没有细讲的老技术一并补充一下。本文尽量写得浅显易懂但是最好结合(一)(二)(三)一起阅读,边玩边看更有助于理解。
照例先放一些当下最新的效果吸引大家看下去:


说回正题,由于diffusion超强的学习能力,理论上网络是可以还原出训练集里的每一张数据的,所以只要数据足够多足够好,模型就可以生成非常好的图片。和人学画画不同,如果人的难点是画不出来,那么模型就是不知道该往哪个方向画。所以控制模型生成其实就是想办法方式让模型听话,按照你的指示生成结果。
在之前的《浅谈AI画画(二):文字如何控制画面内容》中,我简单展示过AI画画中img2img的效果。当时的原理是把左图加一些高斯噪声(撒撒黑胡椒)然后作为底图来基于它生成。所以基本上色块分布是接近的,但是很难控制更细节的了。

(回头再看去年的配图感觉恍如隔世……)
今年引起爆炸性话题的ControlNet,则是可以通过任何的条件控制网络生成。原来模型只能得到一个文本的生成引导,现在它可以听懂任何基于图片提取的信号了,只要你拿一组成对的图片去训练!
这个方式出来以后极大地扩展了可玩性,而且官方已经提供了非常多常用的训练好的控制网络。你可以用depth控制结构生成各种场景:

可以直接拿线稿上色:

可以随便涂几笔就生成复杂的图片:

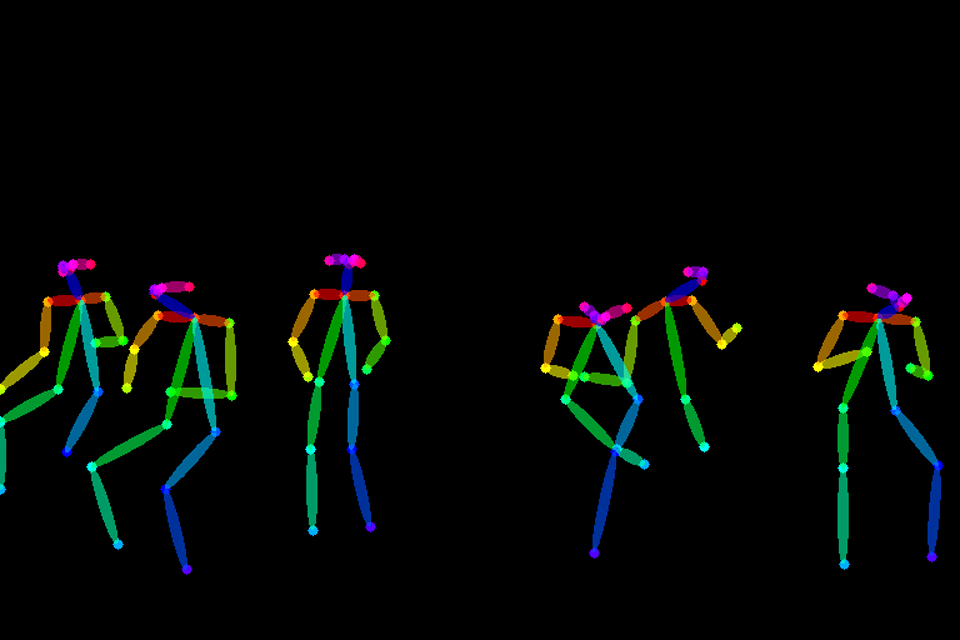
还可以通过姿态检测生成很好的多人结果:

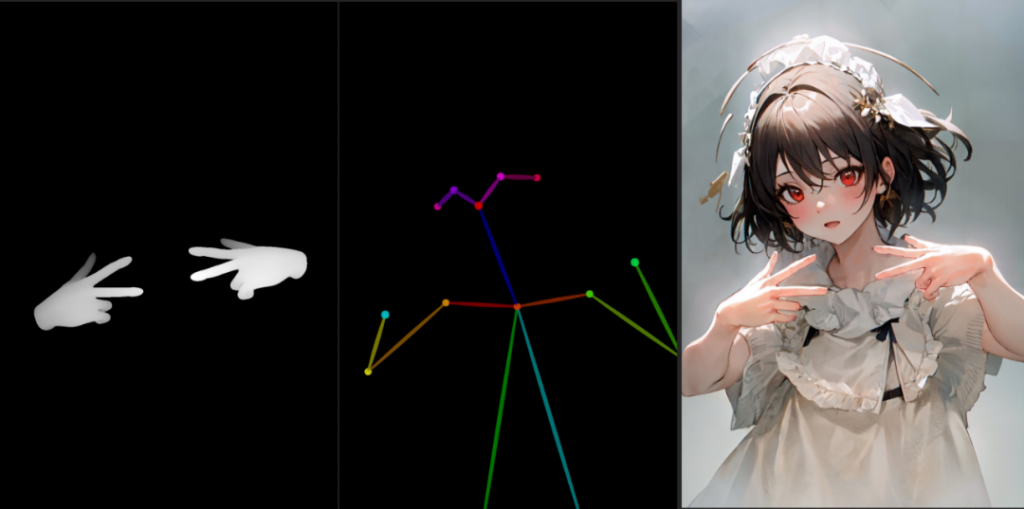
只要你想,你甚至可以自己训练控制网络。比如说就有人训练了手脚的控制器,解决了ai不会画手的问题:
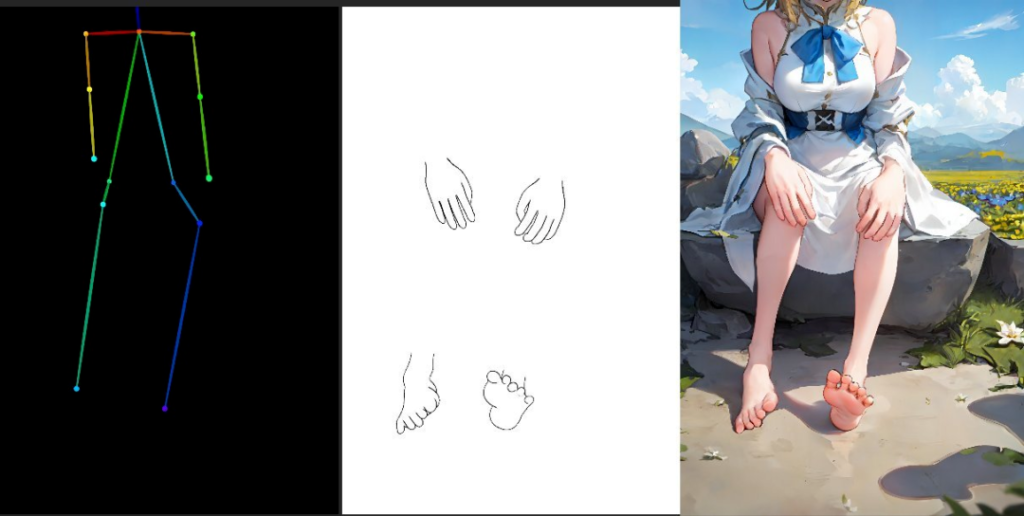
这些控制结果还可以一起用,例如结合人体姿态和深度图:

甚至不需要来自同一张图:

效果是真的非常惊艳,但原理上其实实现得比较简单。为了给原始模型增加额外的条件输入,把整个网络复制了一份,固定原始网络来保证输出的稳定性。原始的网络输入依然是噪声,而复制的control网络的输入是控制条件(深度、姿态等)。把两个输入和输出加起来,用成对的数据集(输入是深度图输出是原图这种感觉)去训练控制网络,达到控制条件能够很好控制生成结果的程度,就训练好啦!并且这个训练本质上还是在做finetune,所以耗时也不算很大,和直接finetune网络差不多。
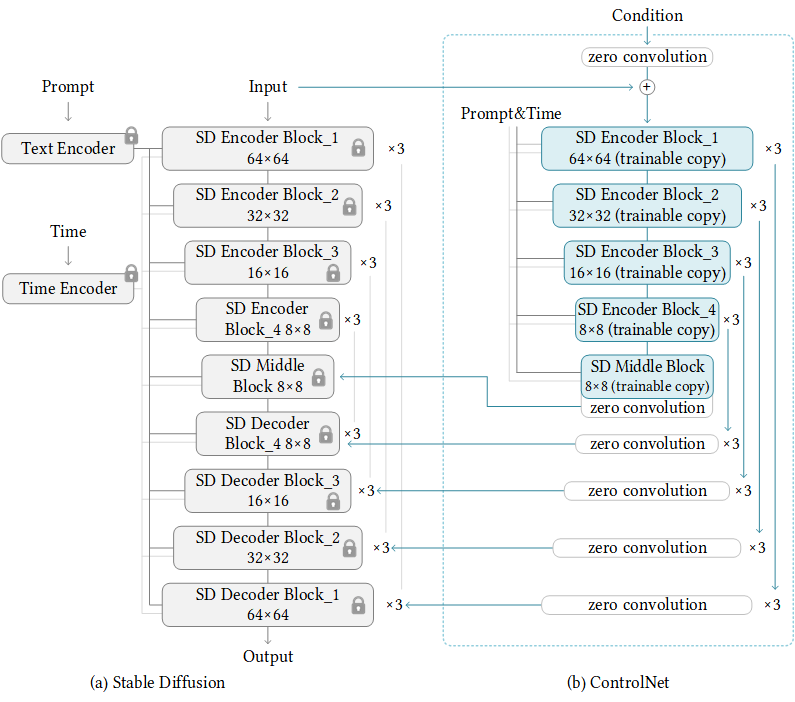
(放个图在这里但我知道没人会看)
ControlNet解决了多人的姿态控制以后,模型已经可以很好生成非常合理的结构了。这时候就会面临另一个问题,模型的细节要如何生成得更好?
想要得到高质量的图片,最直接的方式就是调大输出的分辨率。分辨率越大,细节画得就越好(尤其是人脸)。但是实际上高分辨率的结果非常容易崩掉,比如出现两个身体,因为训练模型里如此高分辨率的图片较少。并且分辨率高了以后计算成本飙升,会算得很慢。

于是一种常见的做法是先生成较小分辨率的结果,然后对图片做超分(就是把图片放大还要保证清晰度):
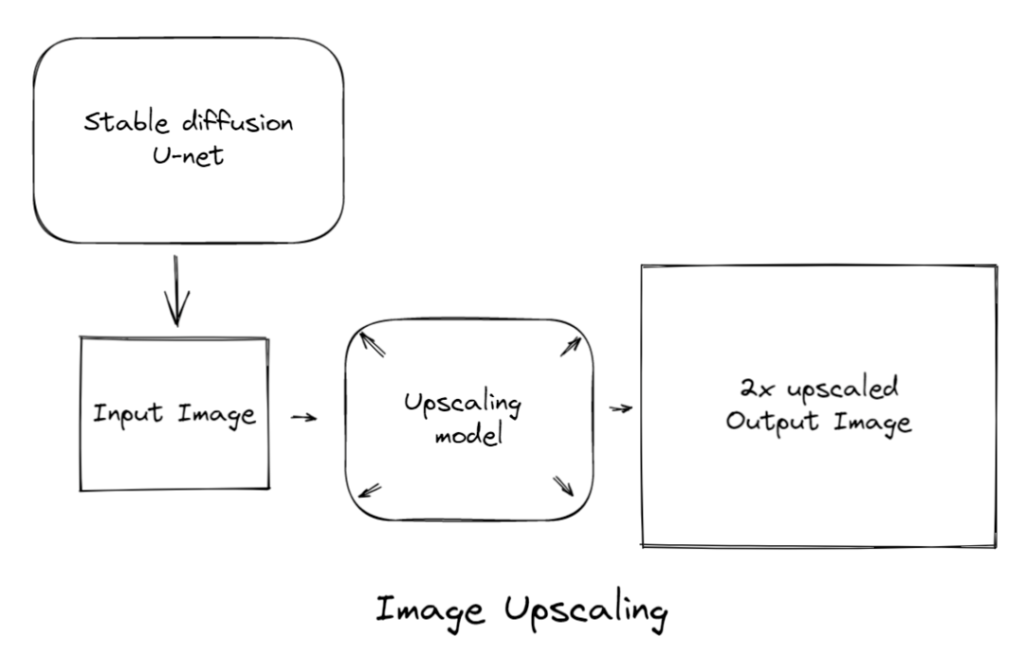
这么做可以保证结构的合理性,而且速度快非常多。但是超分模型对细节的补完不一定能做得很自然,而且容易有过于锐化的结果。除了传统超分模型,还有同样基于diffusion模型的超分算法。由于diffusion相当于重绘了,所以可以得到更好的细节效果。但是图片尺寸非常大,跑起来更慢了。
另一个现在被广泛使用的方法是latent upscale(webui自带的Hires.fix即可实现):

我们之前在《浅谈AI画画(三):为什么AI画画效果如此惊人》写到过,stable diffusion的结构优势之一是它是由压缩图片信息的VAE和对latent进行去噪的U-net网络组成的,所以它天然适合基于latent的超分方法。
Latent upscale就是在图片经过VAE压缩后,直接对latent进行超分,然后再喂给VAE,就能得到x2的图片了。如果和stable diffusion结合,那就是SD的U-net输出latent以后,先过一遍latent upscale,再喂给VAE解码。
当然,对latent做upscale也有基于diffusion的方法并且效果应该是最好的,与此而来的代价就是耗时也增加了。
对图片做普通超分和对latent做基于diffusion的超分结果对比:

个人认为效果好主要是因为diffusion,基于图片做diffusion超分应该也可以达到这个质量,只不过耗时更久,主要是我没跑。
附赠一张latent upscale + controlnet得到的高清美图!美少女果然是第一生产力!明天再和大家介绍一下如何生成AI老婆!
