《浅谈AI画画(一):计算机如何生成图画》解释了计算机如何生成和真实图片相似的图画。
《浅谈AI画画(二):文字如何控制画面内容》解释了模型是如何听懂我们想要它生成什么并给出对应的结果的。
到此为止AI画画的基本原理已经介绍得差不多了。
今天这个系列的最后一篇是选读,但也是2021年后至今AI画画飞速发展关键的一步。虽然主要都是改进的工作,原理上很无聊没什么说头,但是效果是真的很惊人!不过这块涉及到很多训练网络的tricks,也许有一定的基础阅读起来会更轻松。没有基础的朋友们只要记住一句话——你需要很多很多的钱。
现在最火热的模型就是Stable Diffusion,因为开源又效果好得到了众多喜爱。另外基于此吸收了巨量二次元插画的NovelAI也在二次元画风上异军突起,甚至在火热程度上和Stable Diffusion相比有过之而无不及,也是本人入坑的最大契机(谁不想每天的工作就是面对纸片美少女呢)。
讲Stable Diffusion为什么这么好,要先从Latent Diffusion Model谈起。我第一次看Latent Diffusion Model的时候心情和我第一次看CLIP时完全一样:就这?我也能想到啊!只能说这块发展实在是太新了而且非常依赖数据和训练资源,谁能先做出来效果好算谁的。
让我们来复习一下diffusion model的原理:
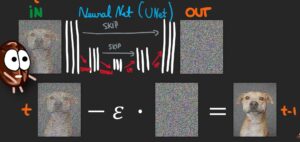
对一个带噪声的输入图片,训练一个噪声预测U-net网络,让它能预测噪声,然后再从输入中减去,得到去噪后的图片。
一般的diffusion model是对原始图片进行加噪去噪,噪声图片和原始图片尺寸是一样的。为了节约训练资源和生成时间,通常会用较小的图片尺寸训练,再接一个超分辨率模型。

而在Latent Diffusion Model中,diffusion模块被用于生成VAE的隐编码。于是整个流程变成了这样:

YouTube - How does Stable Diffusion work?
图片先用训练好的VAE的encoder得到一个维度小得多的图片隐编码(可以理解为将图片信息压缩到一个尺度更小的空间中),diffusion model不再直接处理原图,而是处理这些隐编码,最后生成的新的隐编码再用对应的decoder还原成图片。相较于直接生成图片像素,大幅度减少计算量与显存。
第二个改进是,嗯,又来了,用了很多很多的钱增加了很多很多的训练数据,而且还增加了一个美学评分的过滤指标,只选好看的图片。这一步很关键啊朋友们,这就像是怀孕的时候要多看点美女才能生出漂亮宝宝的都市传说一样(无科学依据请勿模仿)。其实是如果想要学会画漂亮的画就要多看看大艺术家们的masterpieces!
训练集里都是漂亮的图片,比如这样的:

或者这样的:

反正就是什么电子包浆很厚的图啊,模糊的图啊,有水印的图啊,都给干掉了,让机器只从漂亮图片里学画画。
最后相比Latent Diffusion Model的改进是用同样是钱砸出来的训练好的CLIP来让文本控制图片的生成方向。
所以说现在AI领域已经变成大公司的玩具了,动辄大模型大数据普通人实在玩不起,可以称得上某种意义上的阶级垄断。还好这个领域的开源风气还是比较好的,很多优质的数据集和模型都可以免费取用,开源社区也非常有生命力。不知道之后这块还会有多少新的有趣内容产生,小编带您随时关注行业最新进展哦~
顺便浅提一下二次元画风的NovelAI,其实在技术上没有非常新的内容,就是拿巨量二次元图片去finetune原始Stable Diffusion模型。主要一些改进是CLIP用了倒数第二层更贴近文本内容的特征、把训练数据扩展为长宽比不限(为了能容纳下完整的人像)、增加了可支持文本输入长度从而让咒语变得更灵活也更复杂。我个人认为效果好还是因为吞了巨量的图片外加宅宅们的热情让这个模型迅速发扬光大,甚至还有《元素法典》、《参同真解》等众多咒语书。宅宅们的热情真的好夸张啊!
学习了!