上一篇《A浅谈AI画画(一):计算机如何生成图画》解释了计算机如何生成和真实图片相似的图画。接下来解释一下模型是如何理解我们想要它生成什么并给出对应的结果的。
玩过AI画画的人应该都知道,AI画画最主流的模式是在网页输入框中输入一长串吟唱咒语,其中包括想要生成的内容主体、风格、艺术家、一些buff等,点击生成后就可以得到一张非常amazing的结果(也可能很吓人)。
之前在《机器眼中的猫长什么样》中简单介绍过控制模型生成画面最早的做法。当时让AI生成新图片的方法其实更像是让AI生成一大堆图之后再去过一个分类器。在海量的数据面前这显然是不够用的。DALL·E中最值得一提的是引入了CLIP来连接文字和图片。
这个CLIP模型,其实就是用了巨量的文本+图片数据对(互联网可以爬很多很多很多),把图片和文本编码后的特征计算相似性矩阵,通过最大化对角线元素同时最小化非对角线元素,来优化两个编码器,让最后的文本和图片编码器的语义可以强对应起来.

如果不能理解CLIP的原理,只要记住CLIP把文字和图片对应起来了就可以了。它最大的成功之处不是用了多复杂的方法,而是用了巨量的数据。这样带来的好处是,很多现有的图像模型可以很容易扩展成文本控制的图像模型。原本需要大量人工标注的很多任务,现在只需要用集大成的CLIP就可以了,甚至还可能生成新数据,例如在StyleCLIP里用文本交互控制生成的人脸:
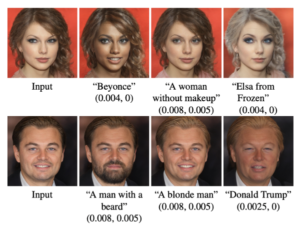
最开始图片的文字信息大多是以打标签的形式通过大量人工标注来完成,有了CLIP以后可以说是彻底打通了文字和图片之间的桥梁,使得图像相关的任务得到大大的扩展,可以说是AI画画的基石也不过分。有了这个CLIP模型,我们就可以计算任意图片和文本之间的关联度(即CLIP-score),拿来指导模型的生成了。
这一步其实还分为了几个发展阶段。最开始用的方法(Guided Diffusion)很naive,就是每次降噪后的图片,都计算一次和输入文本之间的CLIP-score。原本的网络只需要预测噪声,现在网络不但要预测噪声还需要让去噪后的结果图尽可能和文本接近(也就是CLIP-loss尽量小)。这样在不断去噪的过程中,模型就会倾向于生成和文本相近的图片。由于CLIP是在无噪声的图片上进行训练的,这边还有一个小细节是要对CLIP模型用加噪声的图片进行finetune,这样CLIP才能“看出”加噪声后的牛排还是一块牛排。
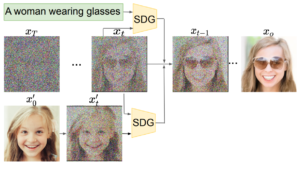
这样做的好处就是CLIP和diffusion model都是现成的,只需要在生成过程中结合到一起。但缺点是本来就已经很慢的diffusion model生成过程变得更慢了,而且这两个模型是独立的,没法联合训练得到更进一步的提升。
于是就有了Classifier-Free Diffusion Guidence,模型同时支持无条件和有条件的噪声估计,在训练diffusion model时就加入文本的引导。这样的模型当然也离不开很多很多的数据和很多很多的卡,除了网络爬取的还有商业图库,构造出巨量的图片和文本对,最后作为成品的GLIDE在生成效果上又达到了一次飞跃。虽然现在看有点简陋,但是在当时来说已经很惊人了,恭喜大家终于追上了21年末的进度!

再衍生一下,如果你玩得更花一点,或者试过AI给你画头像,这时候输入条件就变成了图片,那么这样要怎么控制生成的结果呢?
这里有几种不同的方法,其实算是不同流派了。
第一种是直接提取图片的CLIP特征,就像文字特征一样去引导图片。这样生成出来的结果,图片的内容比较相近,但结构不一定相同。例如下图,模型生成了相似的内容但是完全没有学到超越妹妹的一分美貌呢!

第二种特别好理解,现在主流的AI画画webui里的img2img都是采用这个方法。就是对输入的原图增加几层噪声,再以这个为基础进行常规的去噪。使用你希望的画风相应的咒语,就可以生成和你原图结构类似但画风完全不同的图片。叠加的噪声的强度越高,生成的图片和原图就差距越大,AI画画的发挥空间就越大。

上图是用这个方法生成的二次元美少女,你把屏幕放远点看这两张图的色块是相近的。因为右边的图片就是基于左边叠加了厚厚的“椒盐”来作为基础生成的,大致的色块结构依然保留了,但模型也加上了自己的想象(通过文本引导)。
第三种方法是用对应的图片去finetune生成网络(Dreambooth),如下图。给模型看很多很多小狗狗的图,让模型的生成结果缩小到狗狗这个范围,这样只需要一些简单的词汇就可以生成各种各样的小狗狗啦!是不是很可爱呢!

下一篇更新会介绍一些AI画画在2022年内效果飞速提升的技术细节,大部分是训练模型的tricks,需要一定的背景知识。只想知道AI画画原理的话看到这篇就可以结束了~