AI画画这个话题从去年DALL·E出来就想写,拖一年才写的后果就是写作速度完全跟不上领域内的发展。
要知道去年的AI画画还是这个画风的:

现在的AI画画已经迅速进化到这个程度:
施法咒语长这样——
film still, [film grain], large crowds, cyberpunk street, street level photograph, Chinese neon signs, time square advertisements, Dark atmospheric city by Jeremy Mann, Nathan Neven, James Gilleard, James Gurney, Makoto Shinkai, Antoine Blanchard, Carl Gustav Carus, Gregory Crewdson, Victor Enrich, Ian McQue, Canaletto, oil painting, brush hard, high quality, (brush stroke), matte painting, (very highly detailed)
生成结果长这样——

关于近期各个模型的惊人结果现在应该已经有很多文章介绍了,这个系列主要想尽可能直白地解释AI画画的原理,但是内容越写越多所以分几篇发出来。因为这块也是最近才开始看,有些地方如果没理解对,欢迎指正和交流。
让我们言归正传,AI是怎么学会画图的呢?
这就要涉及到两个方面了。一个是能生成出像真实图片一样的数据,一个是要听得懂我们想要它生成什么,并给出对应的结果。
首先来说说看如何生成出像真实图片一样的数据。如果之前看过我写的GAN相关的文章:《为什么神经网络可以创造未存在过的人脸》,那么你应该能大致上猜到,一个生成模型先吞进大量的数据(巨量的人类真实图片),然后再学习这些数据的分布,去模仿着生成一样的结果。机器学习的核心无非就是这么回事,难点终究是在如何设计模型让模型能更好学到这样的分布上。
如果是VAE,那就是和原图计算差距,所以生成的结果总是比较模糊。而GAN因为引进了判别器,生成器的图片需要骗过判别器,被当作真实的图片,于是它生成的结果肉眼上看会更加逼真。但是GAN由于要训练对抗网络,实在是太不稳定了,面对吞噬了网络巨量数据的超大规模网络来说非常难以控制。这就是为什么现在的AI画画普遍使用另一个新潮的生成模型——diffusion model。
Diffusion model生成图片的过程看似很简单,其实背后有一套非常复杂的数学理论支撑,复杂到我至今没看懂,所以我就先不写了。让我来解释一下简单的部分!
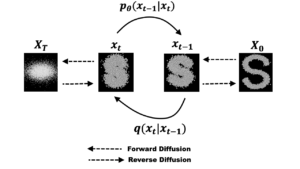
上图是diffusion model生成图片的过程。右边是一个正常的图片,从右到左做的事情是在逐次叠加符合正态分布的噪声,最后得到一个看起来完全是噪声的图片。这就是所谓的“扩散(diffusion)”过程,你可以不严谨地想象成你有一块牛排,你在一遍一遍地往上撒椒盐,一直到整块牛排都被椒盐覆盖看不清原来的纹路。由于每次加噪声只和上一次的状态有关,所以是一个马尔科夫链模型,其中的转换矩阵可以用神经网络预测。
从左到右做的事情是一步步去除噪声,试图还原图片,这就是diffusion model的生成数据过程。
那么为了达到去噪的目的,diffusion model的训练过程实际上就是要从高斯噪声中还原图片,学习马尔科夫链的概率分布,逆转图片噪声,使得最后还原出来的图片符合训练集的分布。
这个去噪的网络是如何设计的呢?我们可以从叠加噪声的过程中发现,原图和加噪声后的图片尺寸是完全一样的!于是很自然能想到用一个U-net结构(如下图)来学习。

U-net是一个类似auto-encoder的漏斗状网络,但在相同尺寸的decoder和encoder层增加了直接的连接,以便于图片相同位置的信息可以更好通过网络传递。在去噪任务中,U-net的输入是一张带噪声的图片,需要输出的是网络预测的噪声,groundtruth是实际叠加上的噪声。有了这样一个网络,我们就可以预测噪声,从而去除掉它还原图片。因为带噪声的图片=噪声+图片。这也是为什么diffusion model会比其他方法生成图片更慢,因为它是需要一轮一轮去噪的,而不是网络可以一次性推理出结果。
以上就是diffusion model生成图片的原理啦!是不是很简单呢!但是背后的数学推导我无论如何都看不懂呢,希望有人来教教我。
下一篇更新会解释如何控制模型生成的结果。