
如果不告诉你,你能看出这张图片中的人是不存在的人吗?如果你看不出来,没关系,大部分人都看不出来,甚至有一个叫Kickstarter的公司利用这个技术行骗。他们在官网挂出的工程师团队照片,几乎都是由AI合成的虚拟人像,实际上是一个只有两个人的空壳公司,却骗过了所有人的眼睛。
这是一张由当下最先进的虚拟高清人脸合成网络styleGAN2生成的不存在的人脸,每刷新一次就有一张新的:https://thispersondoesnotexist.com/ 。StyleGAN2使用了非常复杂的网络架构,但作为开山之作的GAN本身其实蕴含的是一个很简单的博弈论思想。不过说到虚拟人脸生成,有一个不得不提的技术就是VAE,变分自编码器。接下来就简单介绍一下虚拟图像生成领域的两大技术分支——VAE和GAN,以及为什么它们可以创造未存在过的人脸。
VAE,即variational auto-encoder。先讲auto-encoder,虽然叫auto-encoder但是其实包含了编码器encoder和解码器decoder,是一个对称的网络结构。对于一系列类似的数据,例如图片,虽然数据量很大但是其实是符合一定分布规律的,信息量远小于数据量。编码器的目的就是把数据量为n维的数据压缩成更小的k维特征。这k维特征尽可能包含了原始数据里的所有信息,只需要用对应的解码器,就可以转换回原来的数据。在训练的过程中,数据通过编码器压缩再通过解码器解压,然后最小化重建后数据和原始数据的差。训练好了以后,就只有编码器被用作特征提取的工具,用于进一步的例如图像分类等应用中,故称为auto-encoder。
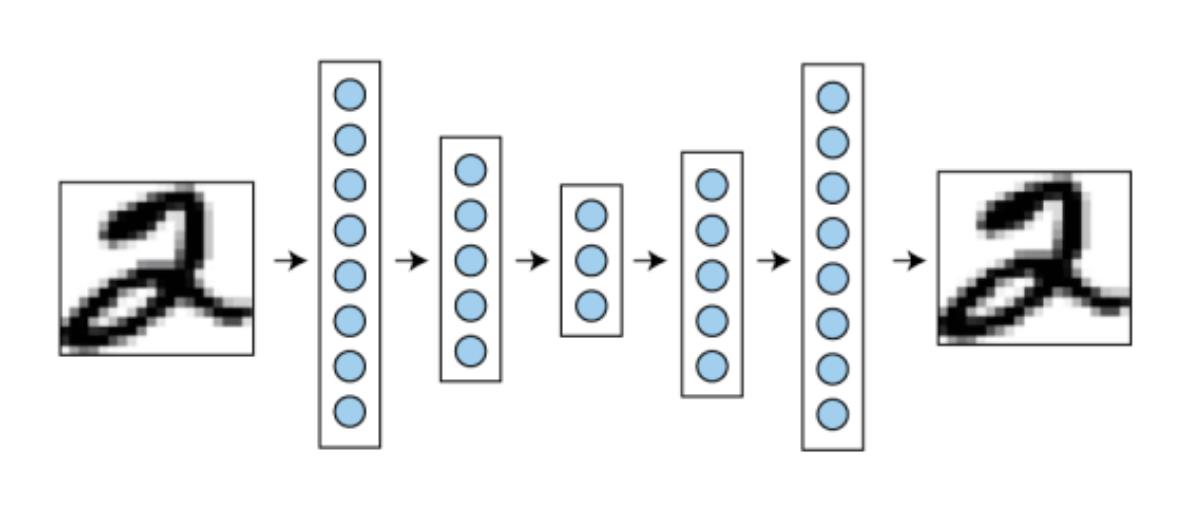
垃圾是放错地方的资源,有一天解码器也被拿出来:你既然可以从k维特征向量恢复出一整张图片,那我给你一个随机生成的k维特征向量,看看你能生成什么。然而实际结果显示,auto-encoder虽然可以“记住”见过的照片,但是生成新图像的能力很差。于是有了variational auto-encoder。VAE在令k维特征中的每个值变成了符合高斯分布的概率值,于是对概率的改变可以让图片信息也有相应的平滑的改变,例如某个控制性别的维度,从0到1可以从一个男性的人脸开始,生成越来越女性化的人脸。

那么VAE其实还是有很多统计假设的,而且我们要判断它生成的效果如何,也需要评估它生成的数据和原始数据的差距大不大。于是有人丢掉所有统计假设,并且把这个评估真(原始数据)假(生成数据)差异的判别器也放进来一起训练,创造了GAN——生成对抗神经网络。

GAN有两个部分,生成器和判别器。生成器从一些随机的k维向量出发,用上采样网络合成大很多的n维数据,判别器就负责判断合成出来的图片是真是假。一开始合成出来的都是意义不明的无规律结果,很简单的判别器就可以分辨出来。生成器发现一些生成的方向,比如有成块的色块,可以骗过判别器,它就会往这个方向合成更多的图片,而判别器发现被骗过去了,就会找到更复杂的特征来区分真假。如此反复,直到生成器生成的结果,判别器已经判断不出真假了,这就算是训练好了。这样训练出来的生成器,可以生成非常逼真,即使是人眼也很难分辨的图片,但是是不存在的。
对于生成器和判别器这样的相互对抗关系,李宏毅老师有一个很恰当的比喻:生成器就是学生,而判别器是老师。但是这个老师的绘画是语文老师教的,他也不会画画。他只有一本课本(真实数据),所以他不能告诉学生应该怎么画,而是只告诉他你画的是对的还是错的。而学生又没有课本,所以只能靠老师给的反馈不断学习,直到学生画的图,老师已经不能和课本里的区分开了,学生就算是学会画画了。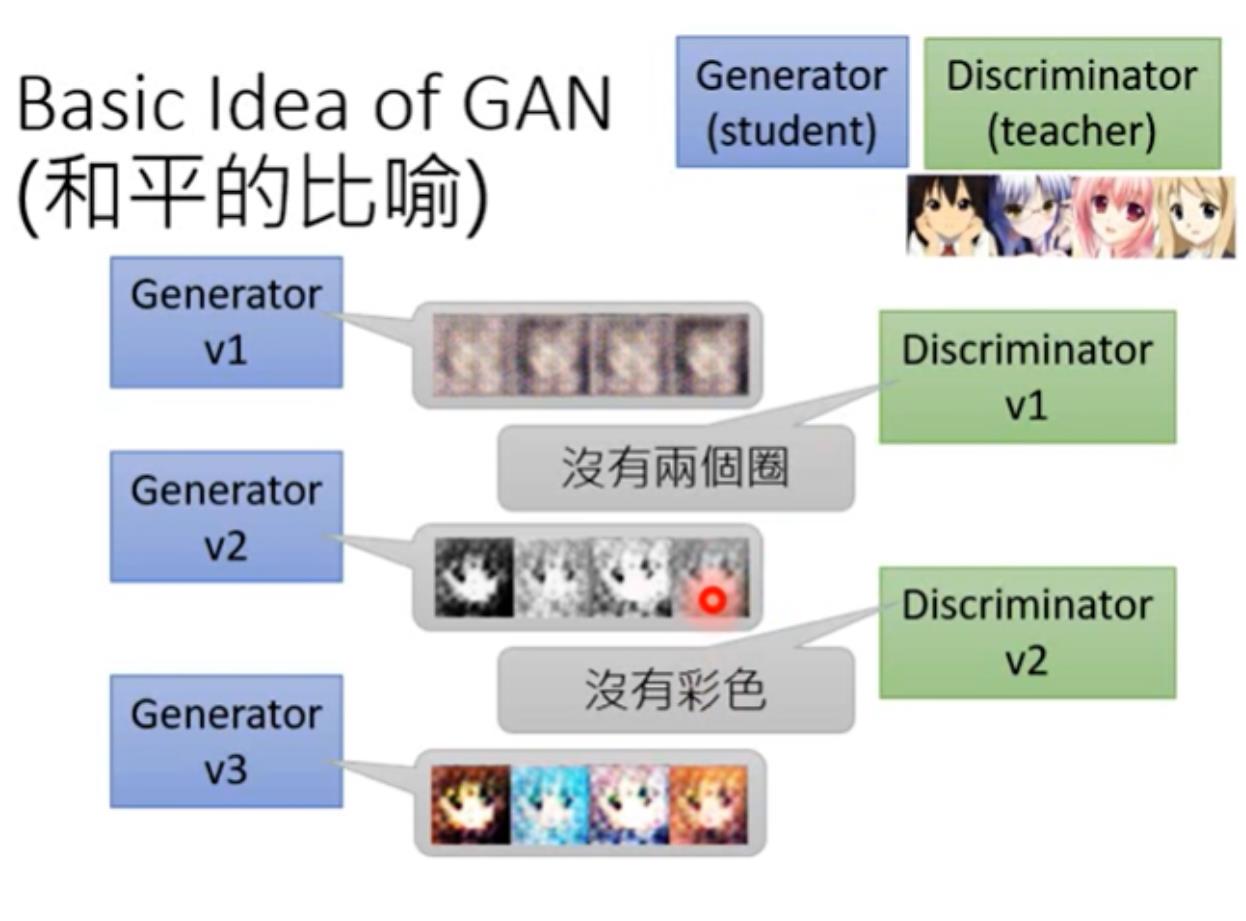
后记:
这篇在草稿箱里呆了太久,本来应该在疫情期间和《机器为什么知道猫是猫》的后续篇合在一起写的,最近重新翻出来趁跑网络的时候改一改先发出来了。相隔半年技术已经又更新换代了不少,看来以后不能攒啊,一攒就过期了。