之前写的是李宏毅的公开课《机器学习的下一步》的第二讲,AI模型的攻击和防御。今天要讲的第三讲的内容是关于可解释机器学习(Explainable ML)。
所谓可解释机器学习,就是希望机器不但可以解答问题,我们还可以知道机器是根据什么解答出这个问题,所谓“知其然,且知其所以然”。大致上机器需要能回答两种问题,以物体识别为例,当机器将一张猫咪图片识别为猫咪的时候:
- 为什么机器认为它是猫?
- 对机器来说,所谓的“猫”是长什么样子的?
为什么让机器回答这个问题很重要?除了我们希望机器更聪明,更接近人类以外,其实有更多实际上的考虑。在实际生活中,当你在利用机器学习做决策时,你不能只给你的客户提供一个最终的解答,大部分时间你还得告诉他,你为什么这么做,例如,银行如何决定是否给一个人批贷款。又或者,你必须确保你的机器是真正学习到了如何做决策,而不是学到了数据中的偏见(bias),也就是通过检查机器学习是如何做决策的,来对模型进行诊断。
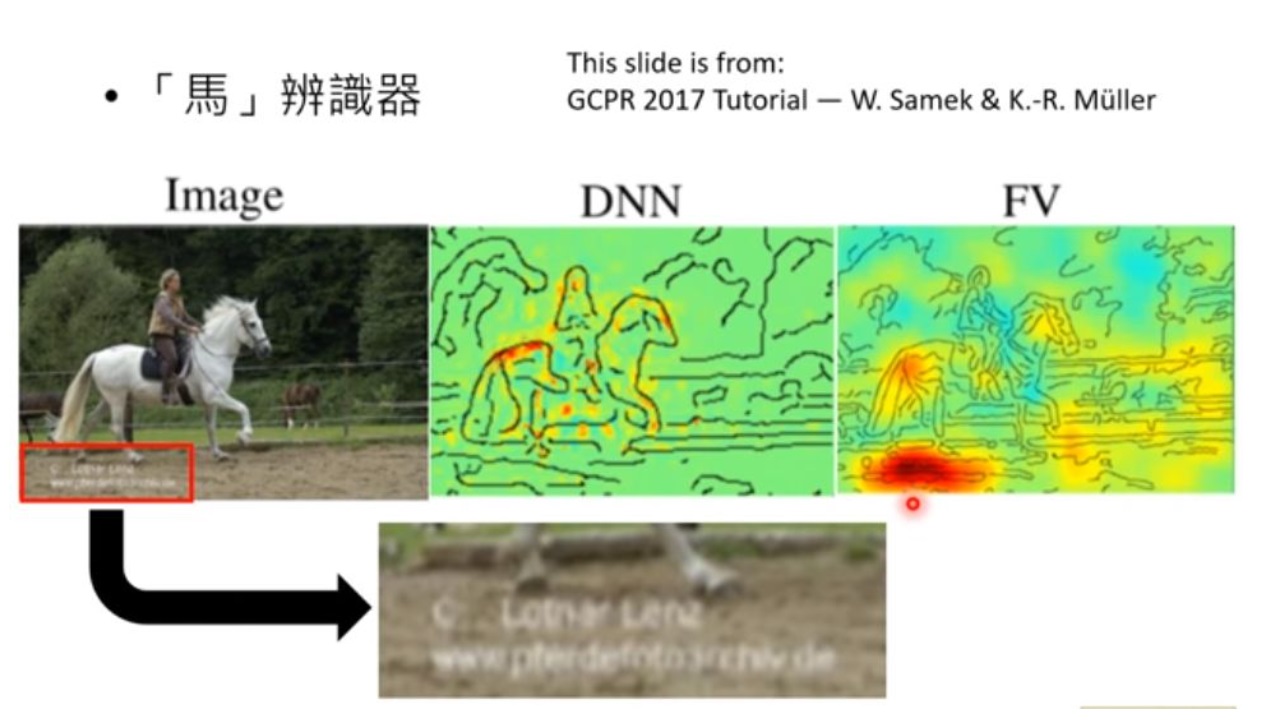
上图是一个辨识是否图片中有马的辨识器,作者用解释模型方法给出了DNN和FV判断图片中有马时“关注”的区域的对比,可以看到DNN主要关注点都在马和上面的人身上,而FV却在左下角有一个特别红的区域,很奇怪。结果分析数据发现,这个数据库里所有马匹的图片全是从一个相同的网站扒下来的,所以左下角有相同的水印。你以为机器学到了如何辨认马,其实它只是学到了看水印而已。这就是一个典型的可解释机器学习在模型诊断上的应用。
从模型的可解释性来说,最简单的线性模型有非常明显的可解释性。线性模型的每一个权值大小就直接反应了各个元素的重要性。然而线性模型能做的事情又是最少的,反而是被诟病为“黑盒子”的神经网络在各个领域上大行其道。一个相对兼顾了可解释性和性能的方法是决策树。决策树的结构本身可以很好解释机器做决策的思路,但通常在解决一个复杂问题时,决策树的结构非常复杂,甚至我们需要用到随机森林,所以可解释性和性能仍然无法很好兼顾。我们与其牺牲性能来换取可解释性,更好的一个选择是,通过某些分析方法,去解释那些好用的模型是如何工作的。
回到第一个问题,机器如何回答:“为什么猫是猫?”这个问题展开来讲,其实是我们希望知道机器做出决策凭据的是什么信息。对于图片来说,我们就是希望确定,机器是根据哪些区域得到答案的。一个比较容易想到的方法是,我们可以通过改变这些信息来看它们对结果的影响程度,例如我们可以对信息进行删减,或是加上一些变化。
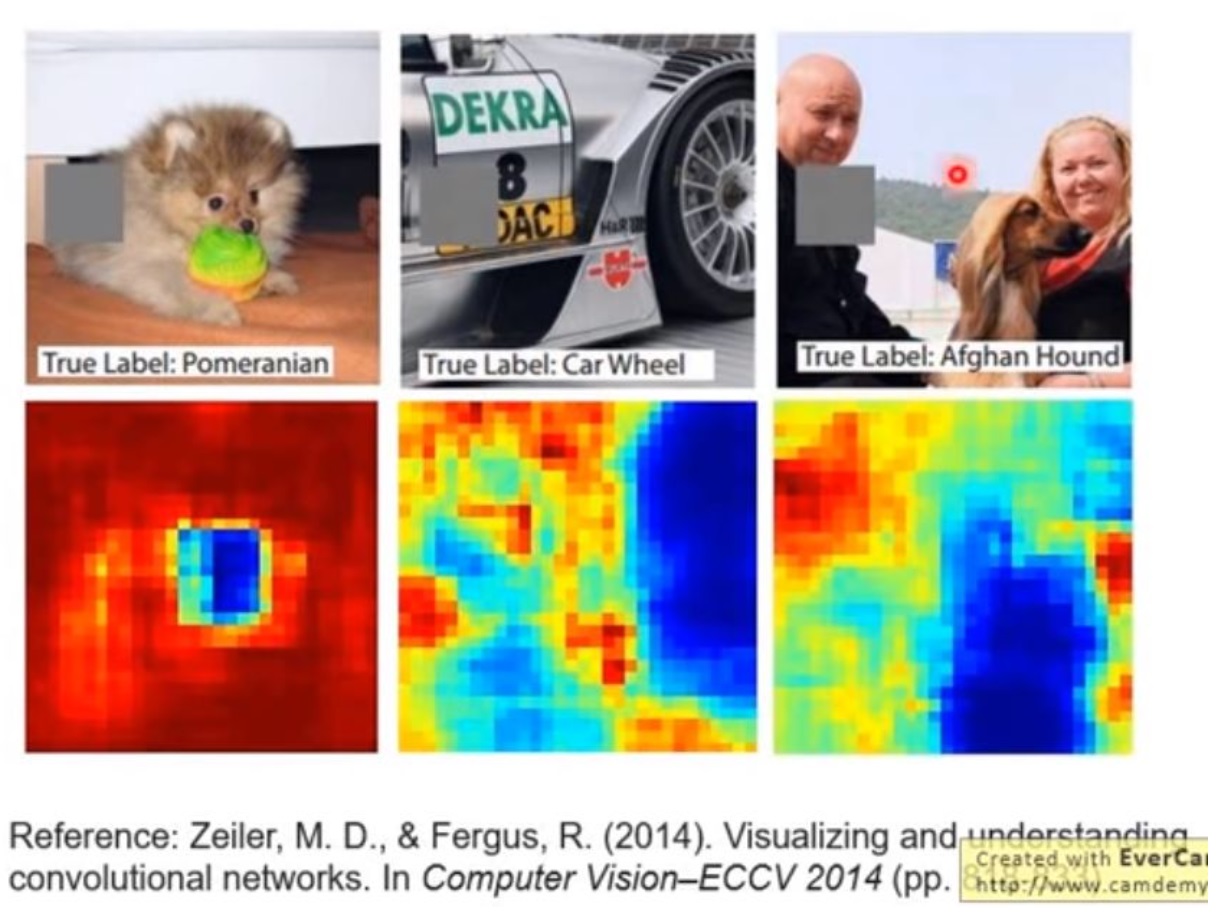
考虑删减的思路,我们可以用一个框框,按顺序把图片的每个角落遮住,再丢给机器学习,让机器学习得出结果(这张图片是猫的概率),如下图,最左边的博美犬和它对应的概率图,概览图的周围几乎都是红色的,代表这些部分被遮住之后机器基本上都还能把图片中的博美犬认出来,但是脸部是蓝色的,说明这部分被遮住了之后,机器很难认出这是一只博美犬。如此一来,机器的判断依据就很显而易见。不过这种做法的弊端是,方框的大小和颜色都可能会影响最终的结果,需要人为设计。
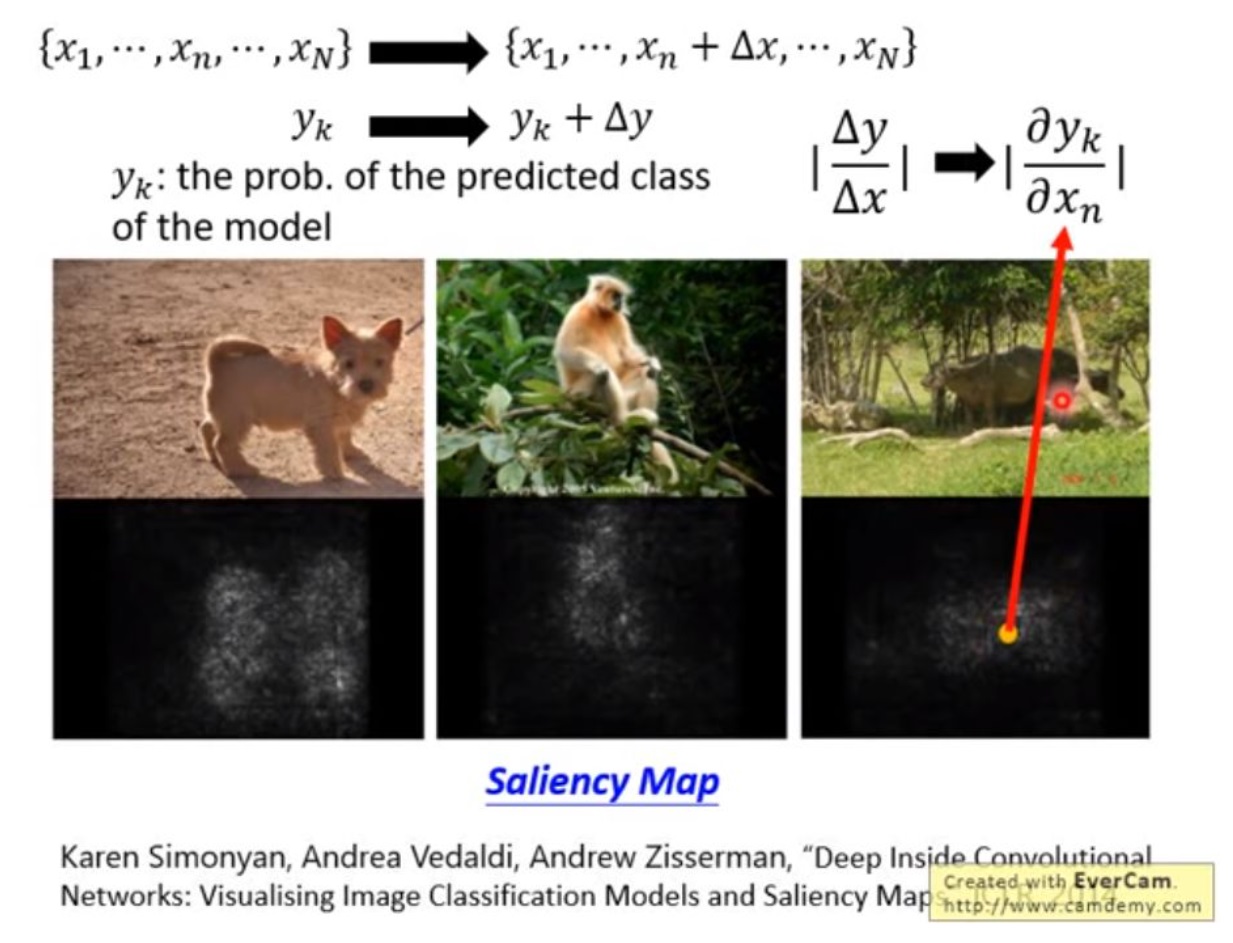
另一个方法是,考虑每个像素的变化对结果带来的影响。给定一张图片,我们对每个像素加上一个小小的扰动,其结果也会产生一个小小的扰动,通过计算扰动的比例,也就是求偏微分,就可以得到一个saliency map,颜色越浅的地方代表其信息对结果影响越大。
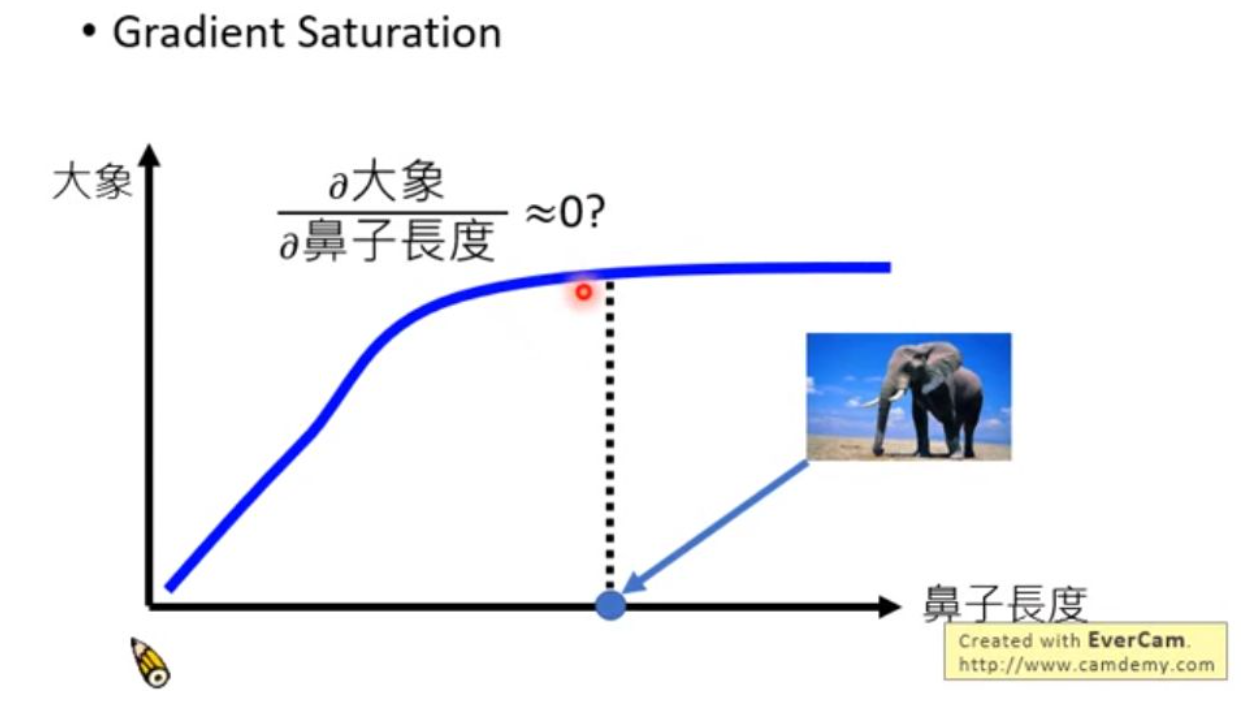
咋一看这么做还挺方便的,其实这个做法有一个比较大的漏洞。例如当我们考虑一个动物是不是大象的时候,我们可能会通过鼻子的长度来判断,鼻子越长,这个动物越有可能是大象。但是当鼻子长到一定程度之后,再继续增长不会让大象更像大象,也就是说梯度会很小,这种情况下基于梯度的算法就会失效。另外,联系上一讲的模型攻击问题,我们也可以知道,模型的结果会因为一些刻意设计的扰动变得很不一样,所以这样的方法很容易受到攻击。
另外有一个更合理也更有意思的做法是,用一个可解释性的模型去解释复杂模型(禁止套娃)。如果我们能用一个可解释性的简单模型,例如线性模型,得到和复杂模型一样的结果,那我们就可以通过可解释性模型的结构来理解复杂模型。可是简单模型和复杂模型的结果怎么可能一样呢?为了解决这个问题,有一个方法叫LIME。
考虑一维的情况,如下图,算法首先在我们想要解释的数据点附近对非线性的复杂模型取样,再用这些样本来拟合一个线性模型,得到和复杂模型在这个范围内相似的线性模型。当然这边也要注意采样的距离,过大也会导致结果偏差较大。

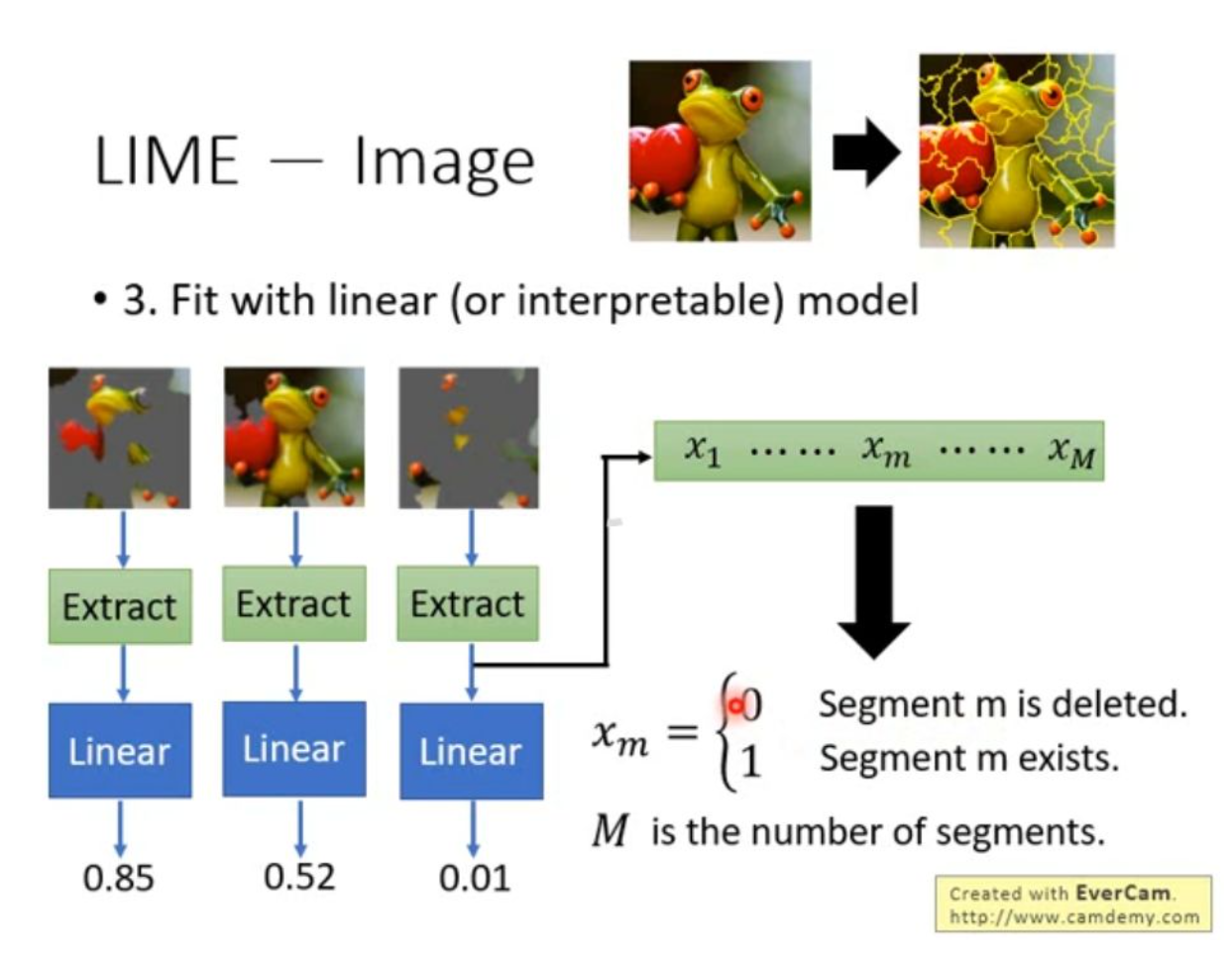
如果把LIME用在图片上,其第一步是对整个图片进行分割,把图片分为不同区域,再用线性模型拟合结果。考虑到图片维度问题,在线性模型之前加上了特征的提取。最后的结果即是一个长度为M的二进制向量,M是分割区域的个数,每个值代表了该区域是否存在。利用这些图片直接从复杂模型得到概率,再通过特征提取得到对应向量,用这一组数据训练线性模型的话,就可以很容易得知哪些区域对于最终的结果是重要的。
这边李举了一个很有趣的例子,他用自己的头像丢到一个识别衣服的判别器里,得到这样的结果:

实验袍很好理解,就是他身上穿的白色衣服当成实验袍了,可是为什么还有0.25的和服呢?用LIME进行分析的结果发现,原来是把他在镜中的倒影里的衣服当成和服了,这么一看好像确实有点像哦?

除了利用线性模型,还有一个办法是利用决策树。这个办法我觉得其实没有LIME直观,只是有一个trick比较值得一提。对于决策树来说,一个决策树结构越简单,那么它的可解释性就越强。这个方法不是尽可能用一个简单的决策树去代表模型,而是在训练模型的时候就让模型对应的决策树尽可能简单,所以作者引入了一个正则化手段叫tree regularization,也就是在loss后加一项和决策树复杂度有关的项。决策度的复杂度是不可求导的,所以难以优化。作者怎么解决这个问题呢?万物皆可神经网络。他另外训练了一个神经网络(我要举报,这人套娃了两次!),可以输入参数得到预测的复杂度。然后再把这个神经网络拿来计算决策树的复杂度,神经网络肯定是可导的,这个问题就变得可以优化了。
那么回到第二个问题,机器眼里的猫长什么样呢?这篇不小心写太长了所以这个问题下篇再写吧,如果这篇还有人看的话XD
图片来源:
[1] 李宏毅-Next Step of Machine Learning:
https://www.youtube.com/playlist?list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4
啊,我好喜歡你這個系列!此方ちゃん請努力! >////u////<
这个系列会一直写的~大概
AI系列文章看得好有收获。感谢!