最近在看李宏毅的公开课《机器学习的下一步》,第二讲的内容是攻击AI模型的,大家可能有印象,之前有个戴副眼镜就会把你辨识为其他人的,那个黄黄的眼镜就是攻击模型用的。那个眼镜长这样:

戴上眼镜,人脸识别系统就会把你识别成其他人,例如大明星。

所谓AI模型的攻击算法,就是这样用一些较为轻微的刻意设计的变化,来欺骗模型,使得模型识别结果失效,或是识别为另一个特定的对象。攻击算法的大致原理是,对于某个样本x0,他在随机方向上产生变化,会在一定范围内较为稳定地识别成特定的结果,然而在某个特定的方向上,只要有一点轻微的扰动,模型的识别结果就会变成其他的对象,如下图:
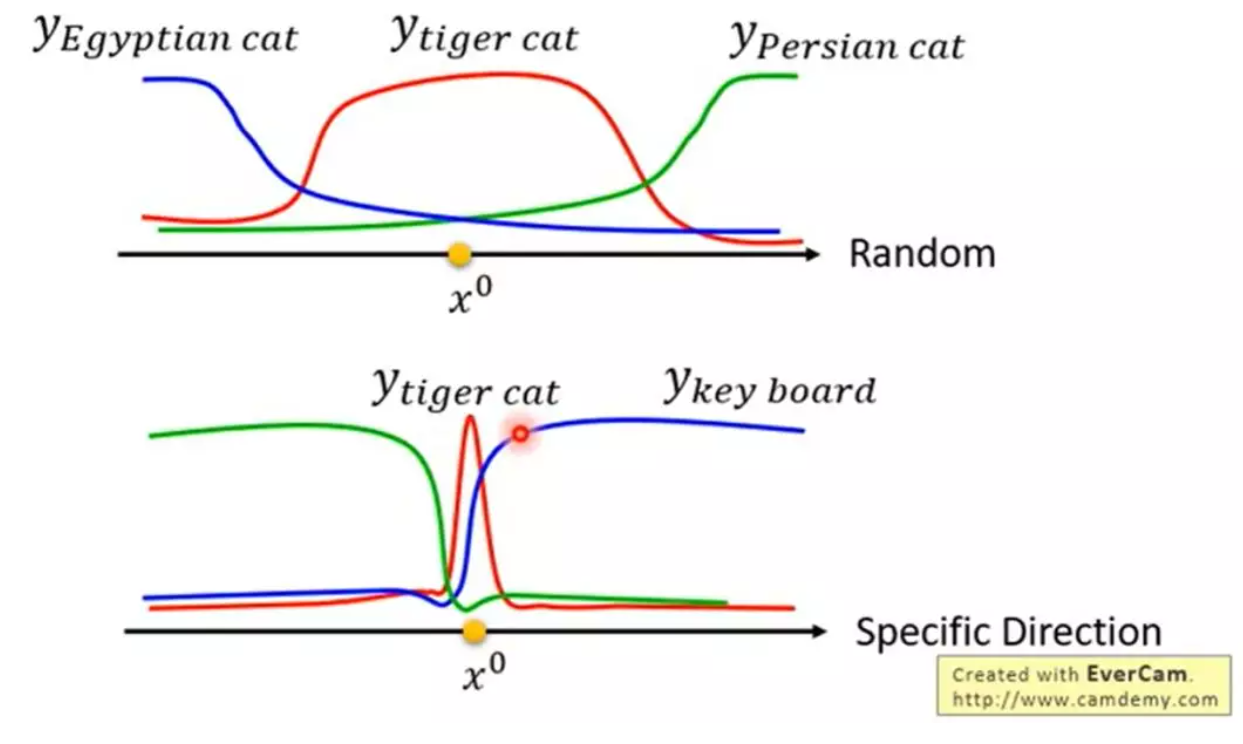
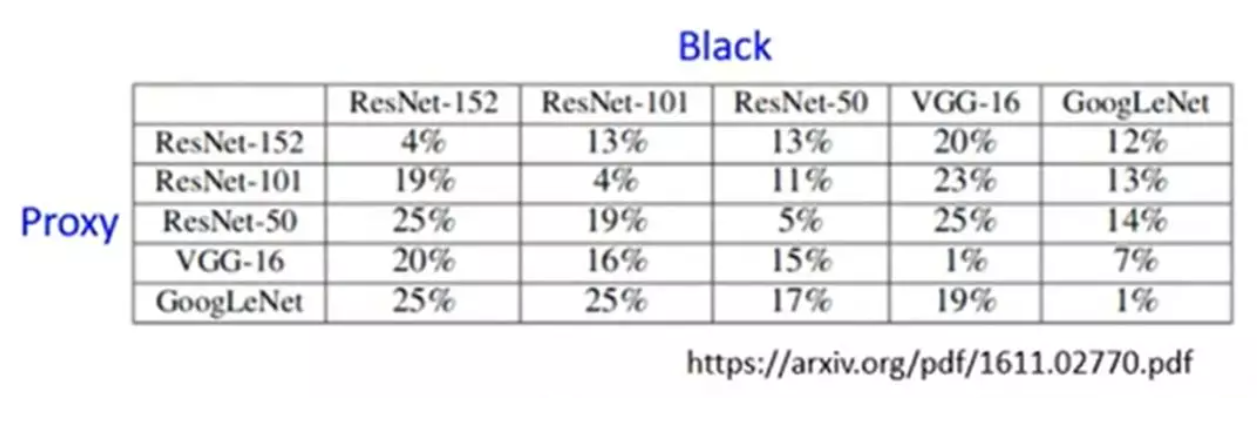
攻击算法的目标就是通过优化算法,找出这样的特定的方向。对于完全公开透明的模型,攻击算法可以很容易搜索出这样的方向(即“白箱攻击”)。而对于黑箱模型来说怎么办呢?实际上我们可以另外用相同的数据训练一个代理模型(proxy)来代替黑箱模型,用代理模型求出的攻击数据,往往对黑箱模型也有一定效果,有人分别用不同的模型做了对比试验,结果如下:
上面主要是介绍攻击算法的运作,那AI模型要如何对抗这样的攻击呢?这样的攻击数据是根据模型刻意设计出来的,所以是不是保管好模型就可以?没用,因为有训练数据就完全可以训练出一个新的模型出来,然后用新的模型设计攻击数据,也就是上面说的黑箱攻击。那保管好训练数据呢?还是不行,只要这个模型是公开使用,就可以通过扔大量数据得到其标签来得到新的训练数据。所以ai模型只要公开使用,就非常危险。
那可以怎么办呢?有两种思路:提前检测出异常数据(涉及到第一讲的异常检测)为模型提供一层屏障,或是把漏洞找出来,补上。
第一种思路(passive defense),例如说是给图片进行平滑化,把一些精心设计骗过人眼的微小噪音磨平,又或者是对图片进行一些随机的裁剪之类的,但依然能辨识出图片本身内容。但实际上这个屏障也可能会被攻击算法视为模型的一部分(例如神经网络的第一层),用同样的方法制造出可以骗过这层处理的新的攻击数据。
第二种思路(proactive defense),更辛苦但是更全面。训练好一个模型以后,用攻击算法去攻击这个网络,然后再把这组数据(也就是使得网络失效的数据和它本应该有的真实标签)放进去更新网络,如此迭代。并且用攻击算法a补上漏洞以后,对攻击算法b依然是无能为力的。所以必须对每种攻击算法都迭代非常多次,才可以得到最终的,非常稳健的ai模型。
题外话:
最初写这篇其实是因为联想到,这次肺炎就像是一个对人类社会文明科技的攻击算法,并且我们经历过太多这样的攻击,每次攻击都是针对一个‘原本就存在的’漏洞,我们就是在一次又一次补上漏洞后得到一个相对稳定的社会环境的,但是漏洞是必然存在的,攻击算法也在更新,我们能做的只有一个个补上,和提前做好防护。
图片来源:
[1] 李宏毅-Next Step of Machine Learning:
https://www.youtube.com/playlist?list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4
[2] 《Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition》M Sharif, S Bhagavatula, L Bauer, MK Reiter