最近的KM简直被Clawdbot霸榜了,但是对于程序员之外的人而言,这个东西虽然很有趣,但实在是入门门槛太高了。反而是最近霸榜推特的Kimi K2.5大模型开源的消息在国内没什么水花。
看了一下它们的技术博客,试用了一天,我感觉这个大模型开源的意义不亚于去年的deepseek R1。它让很多AI 任务的能力,例如前端生成、PPT制作从勉强能用变成能用,使用门槛大大下降。最关键的是这么好用的模型还是开源的!这就意味着腾讯会部署了给我们白嫖(就相当于用腾讯元宝里的deepseek),是的,codebuddy已经部署了KIMI K2.5!非常迅速(codebuddy也超级好用我逢人就推荐!上手特别快,给没什么编程经验的朋友安利了codebuddy+kimi k2.5组合以后她直接沉迷到用光限额)
不过我亲测对于office相关的操作例如生成PPT等,还是Kimi官网的支持最丝滑,就是时不时提示服务器太忙了不给我生成。所以我还是推荐大部分任务用codebuddy里的Kimi K2.5,或者等Kimi的小土豆服务器扩容!
给你们看我一句话让Kimi生成的ppt,输入prompt:
用最浅显易懂的方式给我解释一下,大模型是如何理解图片的? 在图像理解任务上,又是如何训练的?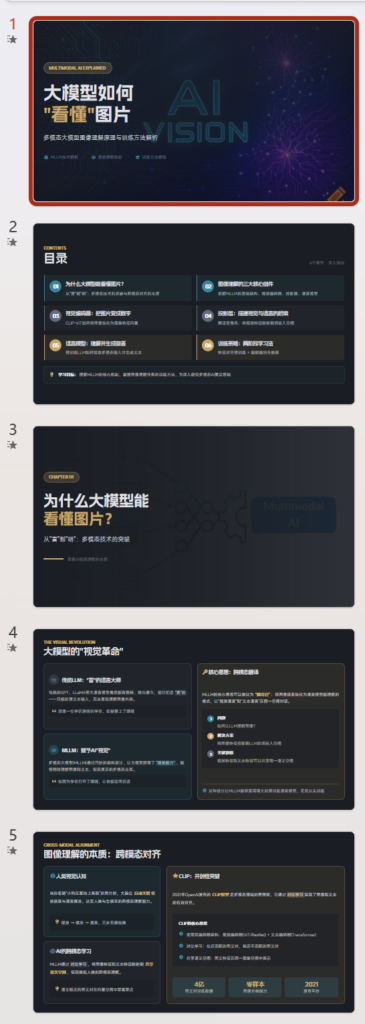
(节选)
生成的初版就直接可用,有逻辑,所有元素可编辑!和之前的相比真的好用太多了!
然后是一句话帮我生成的前端网页(使用codebuddy+Kimi K2.5),输入prompt:
生成一个前端网页html,展示Kimi k2.5的技术更新,内容来源参考这个博客:https://www.kimi.com/blog/kimi-k2-5.html它给我生成了一个很完整的网页,有渲染动画,最后还可以跳转Kimi主页,但我不会贴视频,回头放网页上给你们看下如果我还记得这件事。
之前有尝试过类似manus的产品做网页(sorry用不上正版manus),生成的效果只能说是玩具级别,现在就感觉已经非常接近能用了,而且不需要任何前端知识。
其实前端是设计交互+coding的两个元素叠加,是很适合的应用AI的一个场景,Kimi k2.5在这个方面达到了目前开源中的最佳。在它们的技术博客里展示了更多的例子:
除此之外还支持视频生成网页(复制一个网站的门槛极大降低):
这个video2code的能力真的非常惊艳!以后要复刻一个网站只需要录屏就行了,不需要再截图,语言描述想要的动态效果。
总而言之就我个人而言这是一个非常激动人心的更新,把好多AI功能的使用门槛降低了不少,给周围的朋友推荐后试过的基本上都觉得上手很容易,效果也很惊艳!Kimi是真的不会宣传,去年的发表就被Deepseek盖了一头,今年怎么还要我来当自来水写水军文啊!(快点给我打钱!)
说完了激动人心的效果更新,再提提技术报告里提到的一个非常有趣且重要的概念——Agent Swarm,也就是所谓的智能体蜂群。
传统的Agent是串行执行命令的:
主 Agent(LLM)
↓
生成 Plan
↓
Step 1 → Tool Call
↓
Step 2 → Tool Call
↓
Step 3 → Tool CallK2.5 提出了一个Agent Swarm的概念和PARL(Parallel-Agent Reinforcement Learning) 训练框架,把调用工具变成并行的,例如:
【用户指令:开发深海生物语言】
|
[ K2.5 主协调代理 (Manager) ]
(利用 PARL 技术进行任务拆解)
|
+----------+----------+---------+
| | | |
[子代理 A] [子代理 B] [子代理 C] [子代理 D]
(语音设计师) (语法结构师) (词汇设计师) (神话创作者)
| | | |
+----------+----------+---------+
|
(并行执行:38 分钟内完成)
|
[ 主代理汇总与验收 ]
|
【输出:完整的语言系统 PDF】框架主要含有两个角色:
| 组件 | 角色 | 特点 |
|---|---|---|
| Orchestrator(协调器) | 可训练的"指挥官" | 动态分解任务为可并行化的子任务 |
| Subagents(子智能体) | 冻结的执行单元 | 被动态实例化,并行执行具体任务 |
协调器将复杂任务分解为可并行化的子任务,每个子任务由动态实例化的子智能体执行。不需要人工编写子智能体(如"你是程序员"、"你是测试员")或预设工作流,K2.5 可以自动创建并协调最多 100 个子智能体,执行 1,500 个并行工具调用。
Agent Swarm 有点像Docker Swarm的概念,有一个Orchestrator Agent作为任务分发的管理者去做任务分发
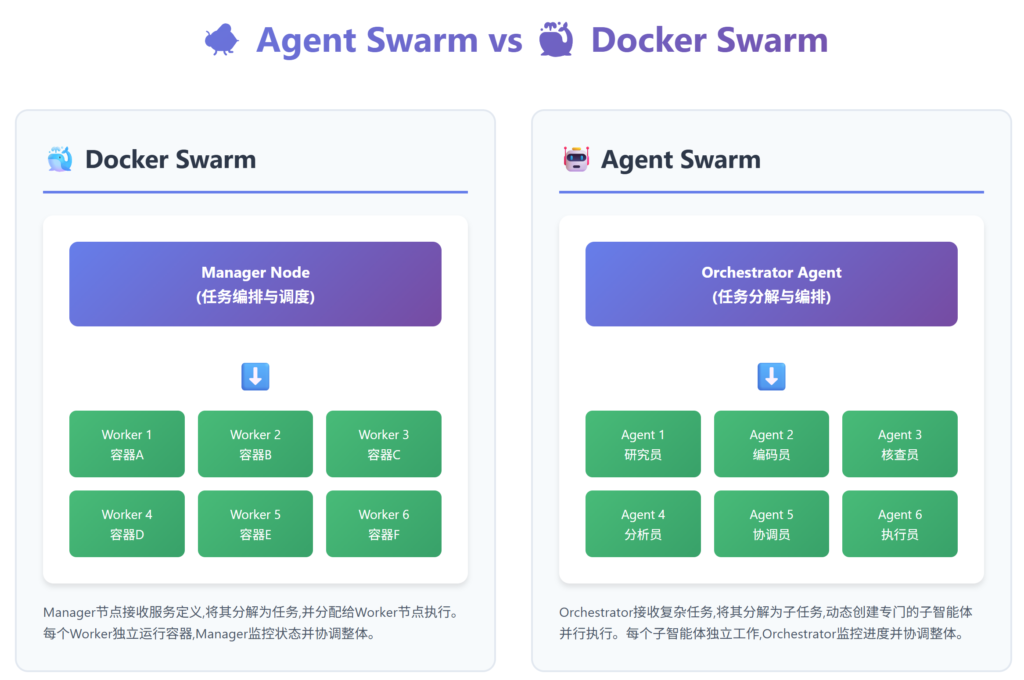
claude给我画的图,画错了打它
关于这样复杂的一个结构是否会影响到模型上下文长度,Kimi的人如此回答:
吴育昕:“智能体蜂群”的一个很酷的点在于,各个子智囊团可以在不“腐蚀”或污染主调度器上下文的情况下独立执行子任务。它们本质上拥有各自的工作记忆,只在必要时将结果返回给调度器。这使我们能够在一个全新的维度上扩展整体的上下文长度。
(出处是《月之暗面三位联创深夜回应一切》第14问)
去年年底的DeepSeek R1通过思维链延长了LLM的深度,通过增加inference耗时巧妙化解了堆砌大模型参数量的做法,而Kimi K2.5的Agent Swarm则又进一步扩展了LLM的深度,更进一步扩展了LLM的能力范围。这也是我认为本次的技术更新不亚于去年Deepseek的原因之一。这个模式给接下来一年的技术发展指明了一个很棒的方向,2026应该会是一个AI Agent大爆发的年份。
另外,在训练这个模式的时候可能会遇到"串行崩溃"的问题——协调器虽然有并行能力,却退化为单智能体执行。
为此,PARL 采用了分阶段的奖励塑形(staged reward shaping):在训练早期鼓励并行行为,随后逐步将优化重点转向任务成功本身。
奖励函数设计:
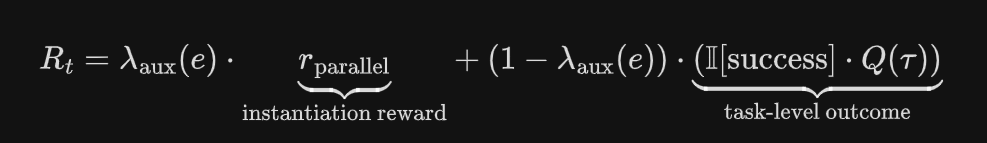
λaux(e)从0.1→0.0逐渐退火,意味着早期重视并行行为,而后期更重视任务是否成功。
为了衡量模型的分工规划能力,相比于直接统计总步数,Kimi提出了一个以时延为导向的评估指标:关键步骤(Critical Steps),其灵感来源于并行计算中的关键路径概念:
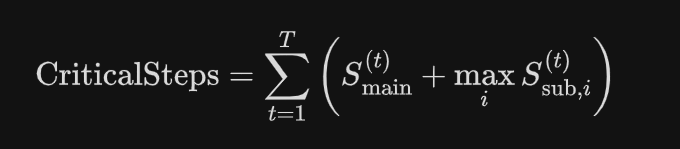
说白话就是并行时按照耗时最长的那个任务计算步数。
Critical Steps 在这里就起到了一个隐式的惩罚作用:
● 如果你简单地增加子智能体数量,但不改善最慢的那个的耗时,指标不会改善
● 只有缩短关键路径时,生成更多子任务才有意义
● 强迫模型学习有效的任务分解:子任务粒度要均匀,依赖关系要最小化,确保所有子智能体几乎同时完成。
这个技术就像一个大脑指挥n个人同时给你干活,一起完成任务。比如让它看100本书,可以分配100个agent各看一本,原本需要100小时的工作1小时就能完成——这只是最简单的例子。更复杂的任务也能被模型自动分解处理。但因为这个功能要花钱,我也是听别人聊的说很好用,实际效果如何待考察,Kimi v我50看看实力?