今天说好了教你们画AI老婆绝不食言!

除了ControlNet,近期AI画画领域另一个不得不提的就是LoRA,上面这个水墨画美少女就是融合LoRA模型生成的。
要讲LoRA就要先解释模型的finetune(微调)。模型的finetune指的是什么呢?其实就是当你有一个现成的,很厉害的大模型(pre-trained model),你想要让它学一些新知识,或者完成一些更面向具体应用的子任务,或者只是为了适配你的数据分布时,就需要拿你的小样本数据去对模型进行重新训练。这个训练不能训太久,否则模型就会过拟合到你的小样本数据上,丧失掉大模型的泛用性。
Pre-train + finetune 是机器学习中非常常见的组合,在应用上有很大价值。但是其中有一个问题就是“遗忘”:模型会在finetune过程中不断忘记之前已经记住的内容。
常见的解决方案,一个是replay,就是也把原始知识过一遍;第二个是正则化,通过正则项控制模型参数和原始参数尽量一致,不要变太多;还有一个是Parameter isolation(参数孤立化),这个是通过独立出一个模块来做finetune,原有的模型不再更新权重。
参数孤立化是其中最有效的一种方式,具体有好几种实现方法。例如Adaptor就是在原模型中增加一个子模块,固定原模型,只训练子模块。是不是听起来很熟悉?是的,ControlNet就是一种类似Adaptor的方法,同理还有T2I-Adapter,也是通过增加子模块来引入新的条件输入控制。
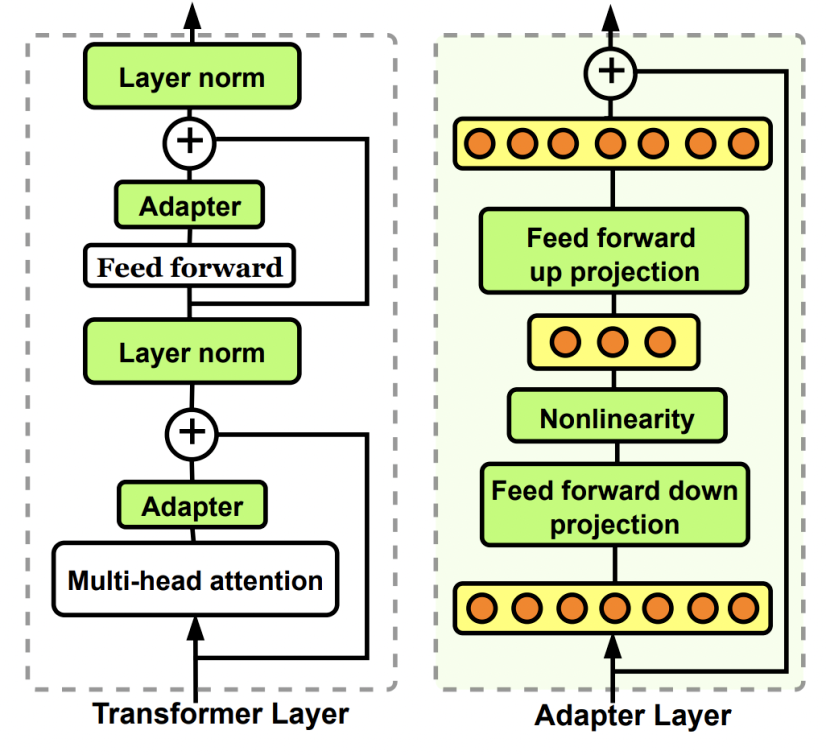
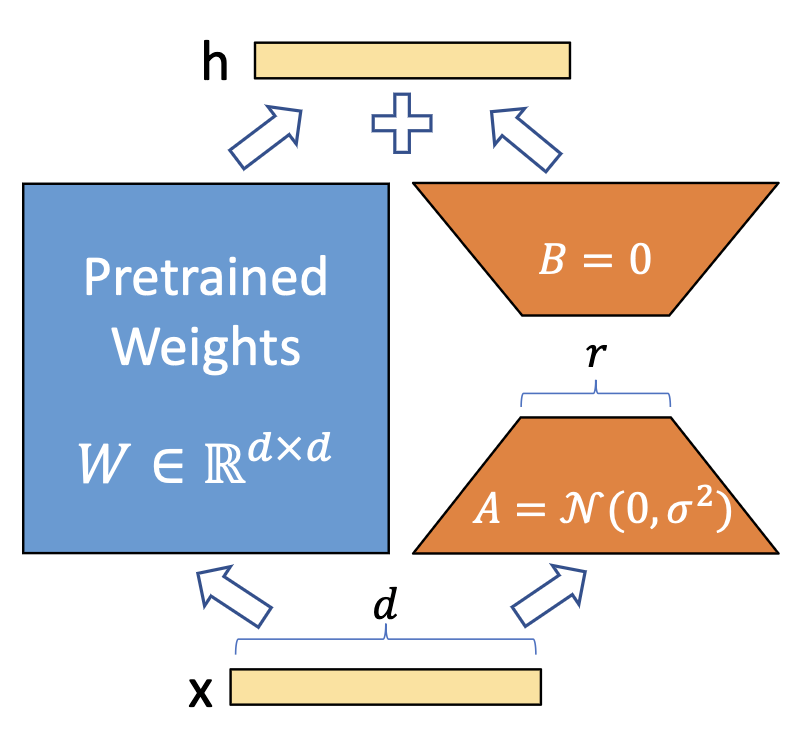
LoRA则是另一种参数孤立化策略,也在AI画画找到了用武之地。它利用低秩矩阵来替代原来全量参数进行训练,从而提升finetune的效率。
我们可以和之前最常用的finetune方法DreamBooth对比一下。
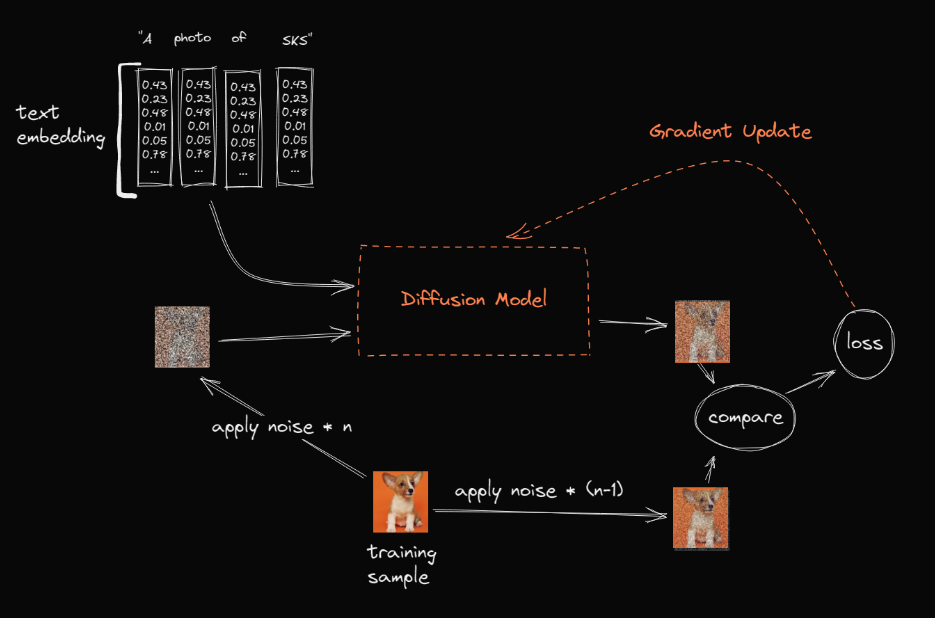
对于DreamBooth来说,它是直接更新整个大模型的权重来让模型学习新概念的。虽然可以通过正则项避免遗忘,但是finetune后的模型依然非常大(和原模型一样大)。
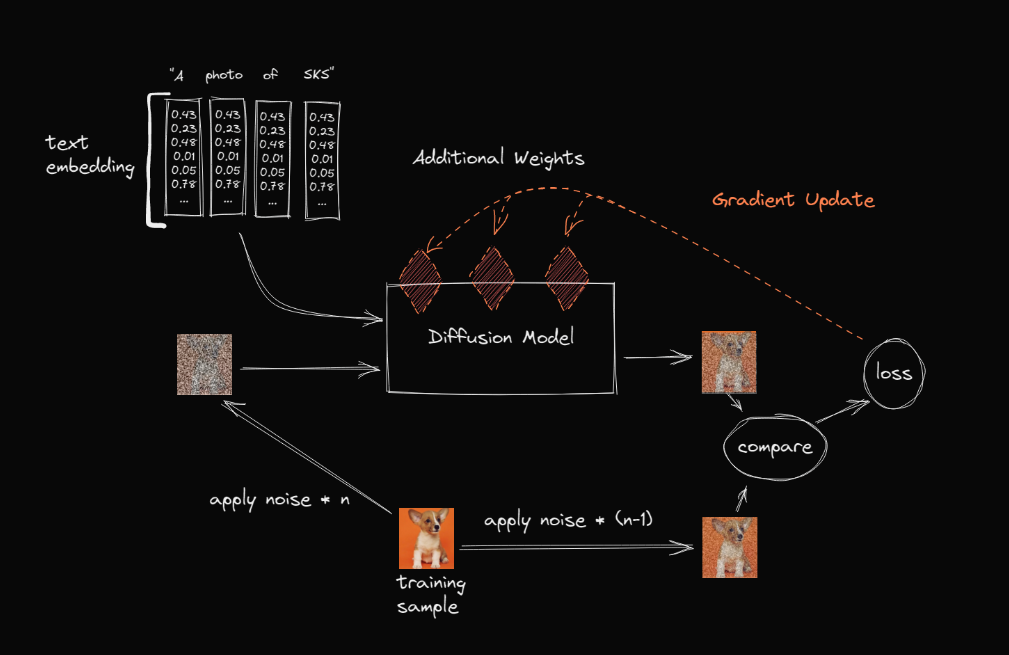
而使用LoRA后,LoRA影响的只是其中一小部分(通过低秩矩阵叠加到大模型网络上的)权重,所以finetune起来更快,更不吃资源,而且得到的finetune模型非常小,使用起来方便很多。
由于LoRA在结构上是独立于大模型的,所以它有一个额外的好处是替换大模型可以得到不同的令人惊喜的结果。例如用水墨画训练的一个很好看的LoRA模型“墨心”,结合国风美女的基础大模型,可以生成穿着中式服装的水墨画美少女:

在网友写的《AI纸片老婆生成指南》中,提出的方法就是利用可以生成可爱亚裔女生的真人大模型,叠加从二次元大模型finetune出来的二次元老婆LoRA,来生成带有角色特征的真人coser照片:

而且LoRA也非常方便进行模型融合,比如说增加另一个韩国偶像LoRA,得到的结果就融合了两者的特色:


在使用上来说,LoRA很像是模型的“插件”,你可以在基础模型上叠加你想要的效果,或者把各种你想要的效果加权组合叠在一起,可以产生很多令人惊喜的结果。
当然LoRA由于是finetune模型,所以画风会趋于单一,是好是坏见仁见智,在需要固定画风或ID的时候能发挥令人惊喜的用处。
使用现实中的真人照片训练LoRA并公开模型非常缺德,请不要这么做。
讲完LoRA和ControlNet了再顺便提一嘴它们的结合产物——mov2mov,来看看效果:
其实原理上就是组合了之前各种技术。例如img2img来保证背景和主体的连续性,controlnet提供更多控制条件来增强对应性,还需要LoRA来保证输出的结果能尽量一致。除此之外,传统的视频防抖算法如窗口平滑、插帧,这些buff全部叠加上去,才可能得到一个依然很抖的效果。
但是其中最最最最最重要的是,你需要一个高质量的驱动视频。如果再看看它的原始视频,是不是就没有那么惊艳了?
可以看到在几乎算是重绘MMD的情况下(简单中的简单模式了)视频效果依然不算理想,想要有更好的视频生成效果还是有一段距离的。